
Many organizations implement intelligent document processing pipelines in order to extract meaningful insights from an increasing volume of unstructured content (such as insurance claims, loan applications and more). Traditionally, these pipelines require significant engineering efforts, as the implementation often involves using several machine learning (ML) models and orchestrating complex workflows.
As organizations integrate these pipelines to customer facing applications (such as web applications for customers to upload documents such as insurance claims, loan approval documents and more), they set goals to provide insights in real time to increase the end customer experience. These organizations also aim to run and scale these workloads with minimal operational overhead and optimizing on costs. In addition, these organizations require the implementation of common security practices such as identity and access management, to make sure that only authorized and authenticated users are allowed to perform specific actions or access specific resources.
In this post, we show you a solution to simplify the creation of an intelligent document processing pipeline, with a web application for customers to upload their files (documents and images) and derive insights from it (summarization, fields extraction and classification). The solution primarily use serverless technologies, it includes a web socket to receive insights in real time and offers several benefits, such as automatic scaling, built-in high availability, and a pay-per-use billing model to optimize on costs. The solution also includes an authentication layer and an authorization layer to manage identities and permissions.
Solution overview
In this post, we provide an operational overview of the solution, and then describe how to set it up with the following services:
- Amazon Bedrock and Amazon Bedrock Data Automation to summarize the content of uploaded files (documents or images) and generate insights from it
- AWS Step Functions and AWS Lambda to orchestrate the summarization and extraction operations, using Amazon Bedrock and Amazon Bedrock Data Automation
- AWS AppSync Events to create a serverless websocket in order for the web application to receive the summarization and extraction insights in real time
- AWS Amplify to create and deploy the web application
- Amazon EventBridge to trigger the orchestration workflow (using AWS Step Functions and AWS Lambda) upon the upload of a new file
- Amazon Cognito to implement an identity platform (user directory and authorization management) for the web application.
- Amazon Simple Storage Service (Amazon S3) to store uploaded files (to be processed by the processing pipeline) and web application-related assets.
The solution architecture is illustrated in the following diagram:
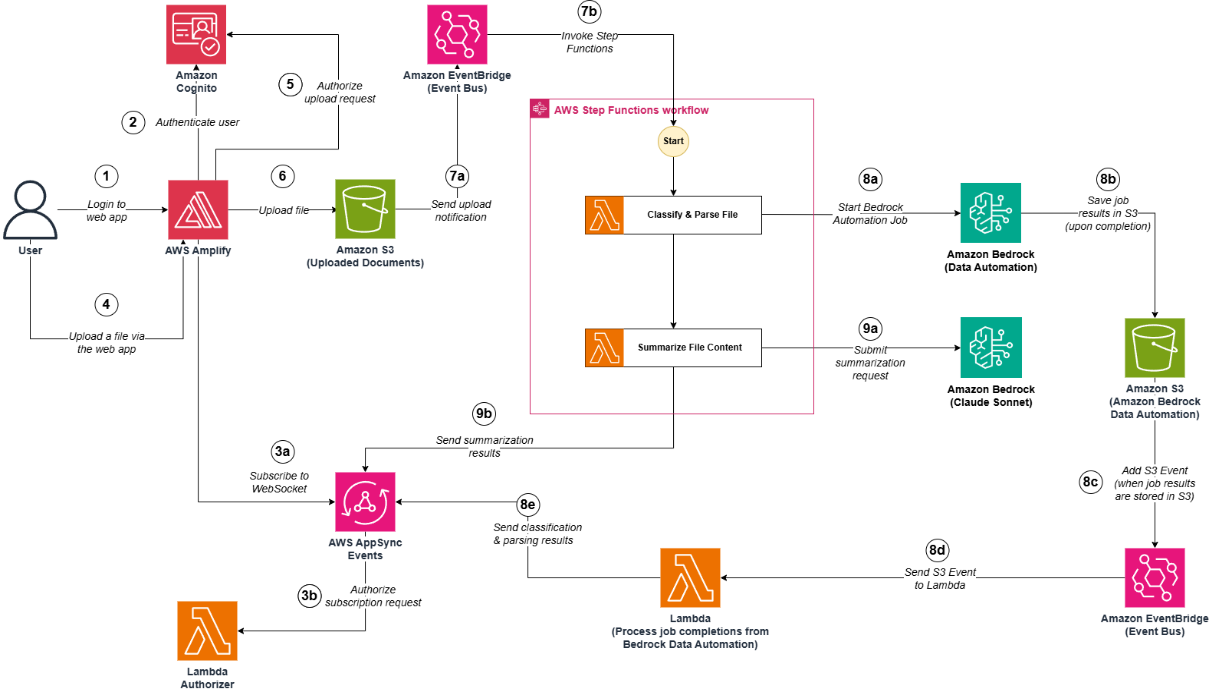
Step 1: The user authenticates to the web application (hosted in AWS Amplify).
Step 2: Amazon Cognito validates the authentication details. After this, the user is now logged in the web application.
Steps 3aand 3b:
- Step 3a: The web application (AWS Amplify) subscribes to an AWS AppSync Events web socket.
- Step 3b: The AWS AppSync Events web socket calls an AWS Lambda authorizer to confirm that the user is authorized to subscribe to the web socket.
Step 4: The user uploads a file (document or image) using the web application.
Step 5: The web application (hosted in AWS Amplify) calls Amazon Cognito (identity pool) to confirm that the user is authorized to upload a file.
Step 6: The file is uploaded in an Amazon S3 bucket.
Steps 7a and 7b: Upon reception of an Amazon S3 upload event (which notifies that the file was uploaded in the Amazon S3 bucket) in the default Amazon Event Bridge bus, an Amazon Event Bridge bus rule triggers the execution of an AWS Step Functions state machine to start the orchestration workflow.
Step 8 (Step to extract fields from a file and classify it):
- Step 8a: The first AWS Lambda function starts a new Amazon Bedrock Automation job (this job extracts specific fields from the uploaded file and classify it)
- Step 8b: Once the job is completed, the results are stored in an Amazon S3 bucket.
- Step 8c and 8d: Upon reception of an Amazon S3 event (which notifies that the results were stored in the Amazon S3 bucket) in the default Amazon Event Bridge, an Amazon Event Bridge bus rule triggers the execution of an AWS Lambda function
- Step 8e: An AWS Lambda function publishes the results to the web socket.
Steps 9a and 9b: The second AWS Lambda function submits a prompt to an Amazon Bedrock foundation model (Sonnet 3), to request a summarization in streaming of the uploaded file. The AWS Lambda function publishes the streaming data to the web socket.
After Step 8e and Step 9b, the user can now consult the summarization result and extraction insights of the uploaded file in the web application.
Pre-requisites
To follow along and set up this solution, you must have the following:
- An AWS account
- A device with access to your AWS account with the following:
- Python 3.12 installed (including pip)
- Node.js 20.12.0 installed
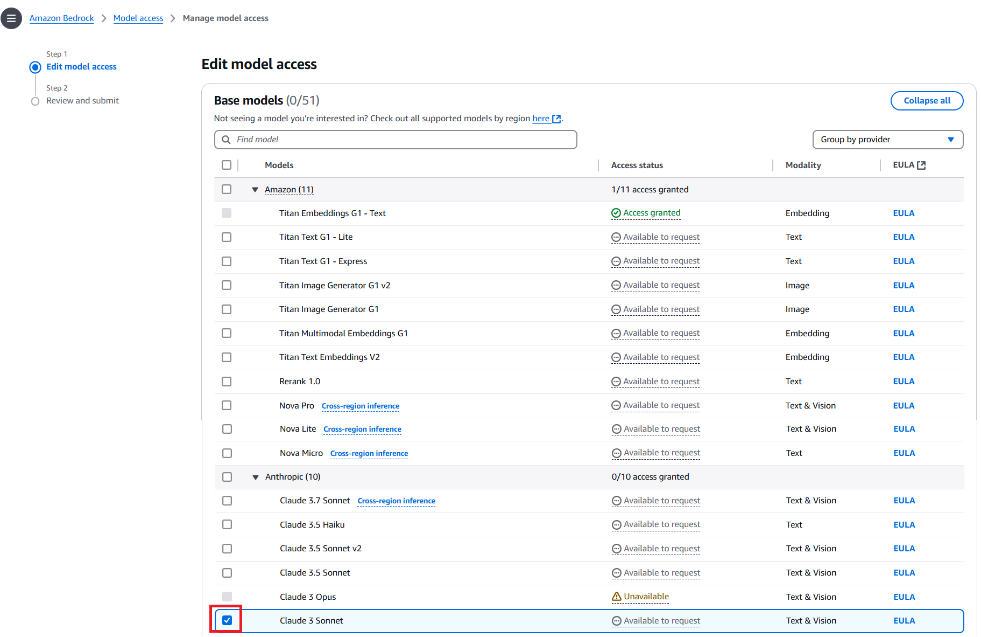
- Enable Model Access to the Claude 3 Sonnet model in Amazon Bedrock
Note: Deploying this solution will incur costs. Review the pricing page of each AWS service used in this post for details on costs. The cost of running this solution will primarily depend on:
- The number of documents (and the size of each document)
- The number of active users
Setup Amazon Bedrock Data Automation
In this section, we setup an Amazon Bedrock Data Automation project and an Amazon Bedrock blueprint.
A project contains a list of blueprints, and each blueprint defines the fields to extract from different types of files (such as documents or images). In this post, we define a blueprint for a driving license.
Complete the following steps to create an Amazon Bedrock Data Automation project and a driving license blueprint:
- Clone the GitHub repository
- Go to the
sample-create-idp-with-appsyncevents-and-amazonbedrockfolder - Initialize the environment (make the shell script files, from the GitHub repository, ready to be used)
- Run the script
setup-bda-project.shto create an Amazon Bedrock Data Automation project and a sample driving license blueprint:
Create the web socket and orchestration backend
In this section, we create the following resources:
- A user directory for web authentication and authorization, created with an Amazon Cognito user pool. An Amazon Cognito identity pool is also created to validate that users are authorized to upload files via the web application.
- A web socket using AWS AppSync Events. This allows our web application to receive real time updates for summarization and extraction results. An authorization layer is also created to protect the web socket from unauthorized users. This is implemented with a Lambda authorizer function to validate that incoming requests include valid authorization details.
- A state machine using AWS Step Functions and AWS Lambda to orchestrate the summarization and extraction operations from the unstructured content
- Amazon S3 buckets to store files for document processing, and code files for AWS Lambda functions
Complete the following steps to create the web socket and the orchestration backend of the solution, using AWS CloudFormation templates:
- Create Amazon S3 buckets used by the solution by running the following script. These buckets will store the files uploaded by users and code files of the AWS Lambda functions used in this solution.
- Create the Amazon Cognito user pool and identity pool by running the
create-cognito-userpool.shscript: - Create the AWS AppSync Events web socket by running the following script:
- Create the AWS Step Functions state machine (including AWS Lambda functions) by running the following scripts:
Configure the Amazon Cognito user pool
In this section, we create a user in our Amazon Cognito user pool. This user will log in to our web application.
Run the script create-cognito-testuser.sh to create the user (make sure to provide your email address):
After you create the user, you should receive an email with a temporary password in this format: “Your username is #your-email-address# and temporary password is #temporary-password#.”
Keep note of these login details (email address and temporary password) to use later when testing the web application.
Create the web application
In this section, we build a web application using AWS Amplify and publish it to make it accessible through an endpoint URL.
Complete the following steps to create the web application:
- Run the script
create-webapp.shto create the web application with AWS Amplify: - Run the script
deploy.shto deploy the web application
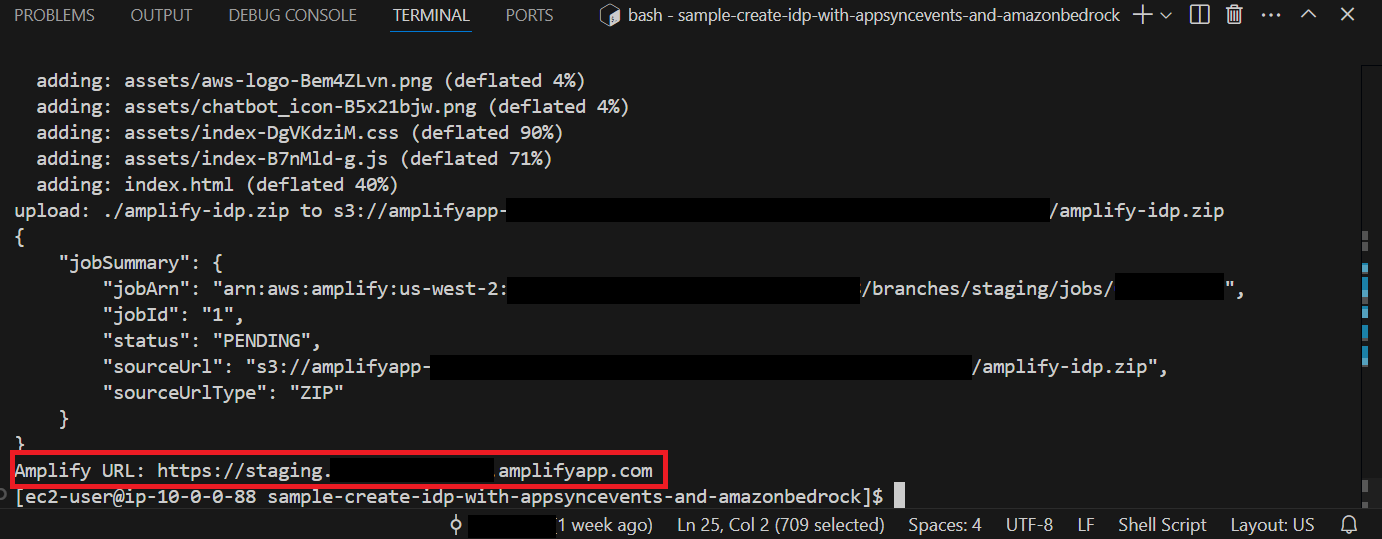
The web application is now available for testing and a URL should be displayed, as shown in the following screenshot. Take note of the URL to use in the following section.
Test the web application
In this section, we test the web application and upload a file to be processed:
- Open the URL of the AWS Amplify application in your web browser.
- Enter your login information (your email and the temporary password you received earlier while configuring the user pool in Amazon Cognito) and choose Sign in.

- When prompted, enter a new password and choose Change Password.
- You should now be able to see a web interface.
- Download the sample driving license at this location and upload it via the web application using either your camera or a file in your local device, as illustrated
Once the file is uploaded, you should start receiving responses in the web application. When all the operations are completed, you should see a result equivalent to what is shown in the following screenshot:
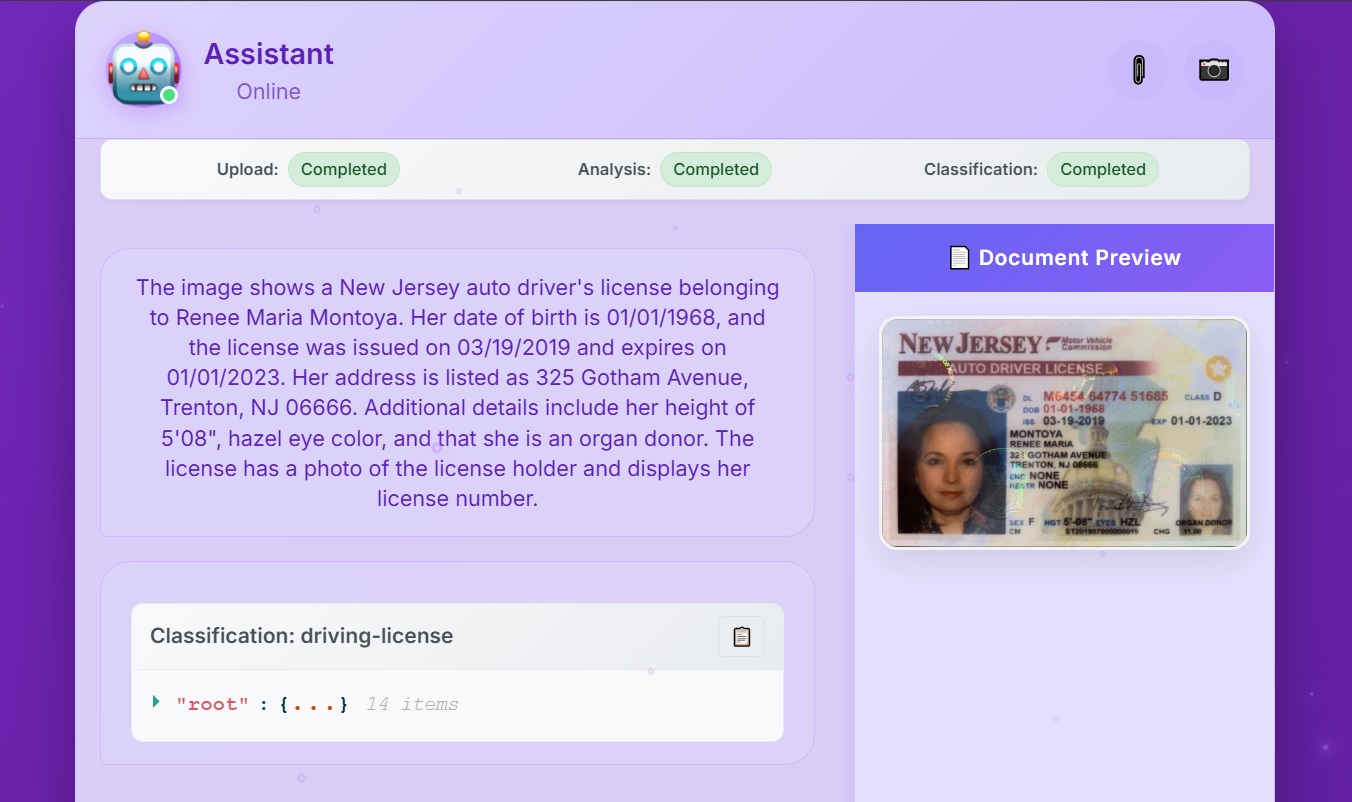
Note: If you are planning to use other driving license sample images with other formats, you may have to update the existing Bedrock Data Automation blueprint we created earlier or define a new blueprint in your Bedrock Data Automation project we created earlier for these new images to work. For more information, please review the Bedrock Data Automation documentation.
Clean up
To make sure that no additional cost is incurred, remove the resources provisioned in your account. Make sure you’re in the correct AWS account before deleting the following resources.
Important note: You should exercise caution when performing the preceding steps. Make sure you are deleting the resources in the correct AWS account.
You can either navigate to the AWS CloudFormation console to delete the CloudFormation stacks associated to the resources provisioned or use the cleanup helper script cleanup.sh available at the root of the sample-create-idp-with-appsyncevents-and-amazonbedrock folder:
Conclusion
In this post, we walked through a solution to create a document processing pipeline, with a web application using serverless services. Via the web application, we were able to upload a file and receive responses in real time for different types of operations (summarization, extraction of specific fields and classification). First, we created an Amazon Bedrock Data Automation project (with a driving license blueprint). Then we created a web socket along with an orchestration solution using a state machine (AWS Step Functions and AWS Lambda functions). We also configured a user pool to grant a user access to the web application. Finally, we created the frontend of the web application in AWS Amplify.
To dive deeper into this solution, a self-paced workshop is available in AWS Workshop Studio.