As you move your generative AI implementations from prototype to production, you may discover the need to run foundation models (FMs) on-premises or at the edge to address data residency, information security (InfoSec) policy, or low latency requirements. For example, customers in regulated industries, such as financial services, healthcare, and telecom, may want to leverage chatbots that support customer queries, optimize internal workflows for complex reporting, and automatically approve requests—while keeping their data in-country. Similarly, some organizations choose to deploy their own small language models (SLMs) to align with stringent internal InfoSec requirements. As another example, manufacturers may want to deploy SLMs right inside their factories to analyze production data and provide real-time equipment diagnostics. To address users’ data residency, latency, and InfoSec needs, this post provides guidance on deploying generative AI FMs into AWS Local Zones and AWS Outposts. The goal is to present a framework for running a range of SLMs that address local data processing requirements-based customer engagements.
Generative AI deployment options
The growth in generative AI deployments and experimentation has accelerated with two business deployment options. The first is the use of a large language model (LLM) to support enterprise needs. LLMs are incredibly flexible: one model can perform completely different tasks, such as answering questions, coding, summarizing documents, translating languages, and generating content. LLMs have the potential to disrupt content creation and the way people use search engines and virtual assistants. The second deployment model is the use of SLMs, addressing a specific use case. SLMs are compact transformer models that primarily use decoder-only or encoder-decoder architectures, with typically less than 20 billion parameters, though this definition is evolving as larger models become available. SLMs can achieve comparable or even superior performance when fine-tuned for specific domains or tasks, making them an excellent alternative for specialized applications.
In addition, SLMs offer faster inference times, lower resource requirements, and are suitable for deployment on a wider range of devices, making them particularly valuable for specialized applications and edge computing where space and power supply are limited. While SLMs are limited in scope and accuracy compared to LLMs, you can enhance their performance for specific tasks through Retrieval Augmented Generation (RAG) and fine-tuning. This combination produces an SLM capable of responding to queries relating to a specific domain with a comparable level of accuracy to an LLM, while reducing hallucinations. SLMs offer effective solutions that balance user needs with cost efficiency.
Architecture overview
The solution discussed in this blog post uses Llama.cpp, an optimized framework written in C/C++ to efficiently run a range of SLMs. Llama.cpp can run efficiently in a wide range of computing environments, enabling generative AI models to operate in Local Zones or on Outposts without the large Graphics Processing Unit (GPU) clusters typically associated with LLMs in their native frameworks. This framework expands your model choice and increases model performance when deploying SLMs to Local Zones and Outposts.
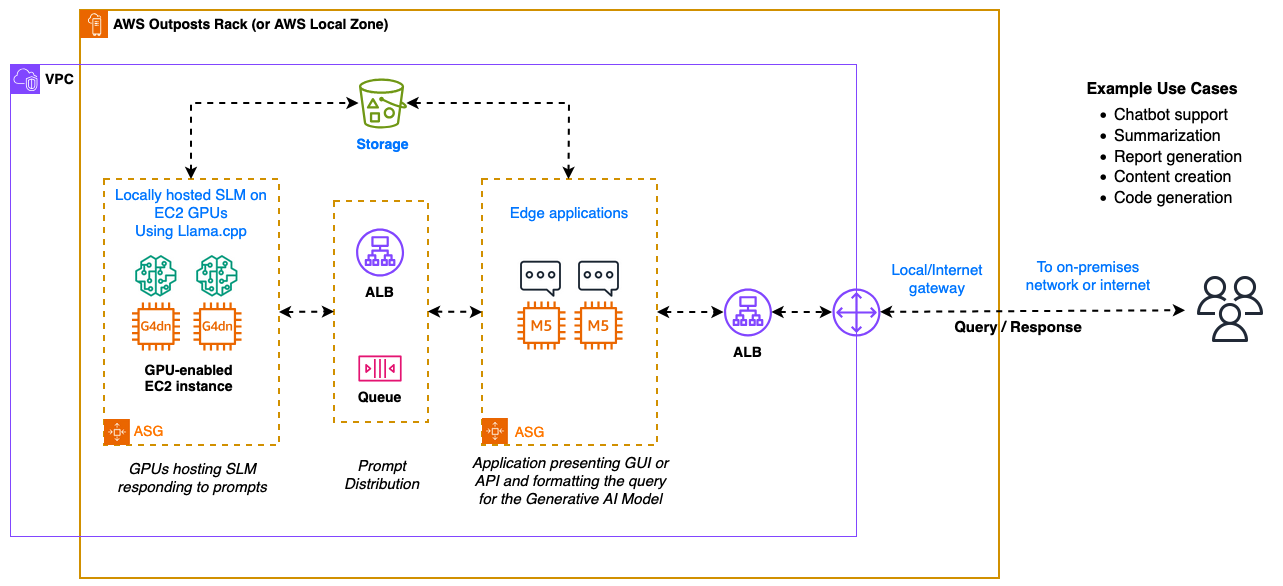
The architecture provides a template for deploying a range of SLMs supporting chatbot or generation use cases. The solution consists of a front-end application receiving user queries, formatting the prompts for presentation to the model, and delivering the resulting responses. To support a scalable solution, the application servers and Amazon EC2 G4dn GPU-enabled instances are front-ended with an Application Load Balancer (ALB).
For a deployment where the incoming prompts exceed the ability of SLMs to service the requests, a message queue can be deployed to the front end of the SLMs. As an example, you could deploy a RabbitMQ cluster to serve as your queue manager.

Figure 1: Architecture overview
Solution deployment
The following instructions show how to launch an SLM using Llama.cpp in Local Zones or on Outposts. Although the preceding architecture overview shows a complete solution with multiple components, this post focuses specifically on the steps necessary to deploy the SLM in an EC2 instance using Llama.cpp.
Prerequisites
For this solution, you need the following prerequisites:
- An AWS account that is either allowlisted for Local Zones or has a logical Outpost installed, configured, and running
- Access to G4dn instances in your account at the chosen location (check availability in AWS Service Quotas)
- A VPC created to host the environment
- Public and private subnets to support the environment in the VPC
- A security group that is associated with your EC2 instance
- AWS Identity and Access Management (IAM) role with AWS Systems Manager Session Manager permissions
1. Launch a GPU instance for your SLM
Sign in to the AWS Management Console, open the Amazon EC2 console, and launch a g4dn.12xlarge EC2 instance in your Local Zone or Outposts environment. Configure it with:
- Red Hat Enterprise Linux 9 (HVM), SSD Volume Type
- A private subnet associated with your Local Zone or Outposts rack
- 30 GiB gp2 root volume and an additional 300 GiB gp2 EBS volume
- The IAM role configured with permissions required for Systems Manager
- SSM Agent to connect to the instance (follow the instructions in Install SSM Agent on RHEL 8.x and 9.x in the Systems Manager User Guide)
For detailed EC2 launch instructions, see Launch an EC2 instance using the launch instance wizard in the console or Launch an instance on your Outposts rack.

Figure 2: SLM instance launched
2. Install NVIDIA drivers
- Connect to the SLM instance using Systems Manager. You can follow the instructions in Connect to your Amazon EC2 instance using Session Manager in the Amazon EC2 User Guide.
- Install kernel packages and tools.
- Install Miniconda3 in the /opt/miniconda3 folder or install a compatible package manager to manage Python dependencies.
- Install the NVIDIA drivers.
3. Download and install Llama.cpp
- Create and mount the filesystem of the Amazon EBS volume you created earlier in the /opt/slm folder. The instructions are available in Make an Amazon EBS volume available for use in the Amazon EBS User Guide.
- Run the following commands to download and install Llama.cpp.
4. Download and convert the SLM model
To run the SLM efficiently with Llama.cpp, you need to convert the model format to GGUF (GPT-Generated Unified Format). This conversion optimizes the model for better performance and memory usage on edge deployments with limited resources. GGUF is specifically designed to work with Llama.cpp’s inference engine.The following instructions show how to download SmolLM2 1.7B and convert it to the GGUF format:
You can also download other publicly available models from Hugging Face as needed, following the same conversion process.
SLM operation and optimization
The deployment of SLMs through Llama.cpp provides operational flexibility through a significant range of environment customization options, allowing you to tailor model behavior to your specific use cases. With Llama.cpp, you can select a range of parameters that can be used to optimize the use of system resources and model operation. This enables models to efficiently use the available resources without consuming unneeded resources or negatively impacting their operation. The following parameters are commonly supported when running Llama.cpp to provide control over how the model runs.
-ngl N, --n-gpu-layers N: When compiled with GPU support, this option allows you to offload some layers to the GPU for computation. This generally results in increased performance.-t N, --threads N: Sets the number of threads to use during generation. For optimal performance, it is recommended to set this value to the number of physical CPU cores that your system has.-n N, --n-predict N: Sets the number of tokens to predict when generating text. Adjusting this value can influence the length of the generated text.-sm, --split-mode: Specifies how to split the model across multiple GPUs when running in a multi-GPU environment. Consider testing the ‘row’ splitting mode as it may provide better performance in some scenarios compared to the default layer-based splitting.--temp N: Temperature is a parameter that provides control over an SLM’s randomness in terms of its outputs. Changing the value from the default of 0.8 changes the distribution of the model’s predictions. Lower values sharpen and deterministically enhance the model’s output, preferring high-probability phrases. On the other hand, a higher temperature fosters more inventiveness and unpredictability, allowing for a wider range of diverse responses. (default: 0.8).-s SEED, --seed SEED: Provides a method to control the randomness of the SLM’s response. Setting a specific seed value produces consistent responses across multiple runs, while using the default value (-1) generates varied responses. (default: -1, -1 = random seed).-c, --ctx-size N: Context size is defined as the number of tokens an FM can process as one prompt (in tokens) into the model. This value reserves memory in the host for the maximum size context length. Reducing the context size can reduce the amount of RAM needed to load and run a model. Models with larger context sizes (>50k) consume more RAM, and in some models, a larger context size can impact accuracy. For example, with Phi-3, it’s recommended to reduce the context size to 8k or 16k. The command to achieve this is –ctx-size XXXX, where XXXX is the context size.
This section demonstrates how to optimize SLM performance for specific use cases using Llama.cpp. We’ll cover two common scenarios: chatbot interactions and text summarization.
Chatbot Use Case Example
Token Size Requirements
For chatbot applications, typical token size requirements include input sizes ranging from 50-150 tokens, which support user questions up to a couple of sentences, and output sizes of approximately 100-300 tokens, allowing the model to provide detailed but concise responses.
Sample Command

Figure 3: Chatbot example
Command Explanation
-m ./models/SmolLM2-1.7B-Instruct-f16.gguf: Specifies the model file to use-ngl 99: Allocates GPU layers for optimal performance-n 512: Sets maximum output tokens to 512, sufficient for the 100-300 tokens typically needed--ctx-size 8192: Defines context window size, allowing for complex conversation history-sm row: Splits the rows across GPUs--temp 0: Sets the temperature to zero to be less creative--single-turn: Optimizes for single-response interactions-sys "You are a helpful assistant": Sets the system prompt to define assistant behavior-p "Hello": Provides the user input prompt
Text summarization example
This command line shows SmolLM2-1.7B running to support a summarization activity.

Figure 4: Summarization example
Cleaning up
To avoid ongoing charges, take these steps to delete the resources you created by following this post, if they are no longer needed.
- Terminate your EC2 instance to avoid unnecessary charges. Furthermore, verify that the 300 GiB EBS volume you attached is properly deleted by checking the Volumes section under Elastic Block Store and manually delete any remaining volumes by choosing them and choosing Actions > Delete volume.
Conclusion
This post took you through the steps of deploying SLMs into AWS on-premises or edge environments to address local data processing needs. The post first discussed business benefits of SLMs, including faster inference time, reduced operational costs, and improved model outcomes. SLMs launched using Llama.cpp and optimized for specific use cases can effectively deliver user services from the edge in a scalable manner. The optimization parameters described in this post provide multiple ways to configure these models for different deployment use cases. You can follow the deployment steps and techniques in this blog post to implement generative AI capabilities that align with your specific data residency, latency, or InfoSec compliance needs while operating efficiently within the resource constraints of edge environments. Visit the following pages to learn more about AWS Local Zones and AWS Outposts.